Inquivix HQ
1-903, 18 Eonju-ro 146-gil,
Gangnam-gu, Seoul, Korea
06057


If you’ve ever wondered what technology search engines use to crawl websites, then get ready to finally get your questions answered. You’ll what a web crawler is, the many different types of web crawlers used by major search engines, and what the search indexing process is all about. You will also learn how all of this will affect search engine results, and how website owners can tell the search engine web crawlers to index content according to their wishes. Let’s find out more about this technology search engines use to deliver billions of relevant search results accurately to people that are looking for information on the world wide web.
What Are Web Crawlers Or Search Engine Bots?
Web crawler bots also known as spiders are automated programs that companies like Google and Microsoft use to teach their search engines what is present on every accessible web page of every website they can find on the internet. It is only through learning what information is included on a web page can these search engines accurately retrieve this information when one of their users types a search query requesting to know about a specific topic.
The Types Of Web Crawler Bots
Every search engine has its web crawlers. Here are some of the most widely used ones.
GoogleBot
Google is the most popular search engine on the planet and uses two versions of web crawlers to index hundreds of billions of web pages. The GoogleBot Desktop will look at pages mimicking the behavior of someone using a desktop computer to browse the internet while the GoogleBot Mobile will do the same for smartphone users.
The GoogleBot is one of the most effective types of search bots ever made and can quickly crawl and index web pages. It does however have some trouble crawling very complex website structures. Furthermore, it can often take GoogleBot many days or weeks to crawl a web page that is newly published, meaning it won’t appear in relevant results for a while.
Bingbot
The Bingbot is Microsoft’s answer to Google on their own search engine Bing. This works similarly to Google’s web crawler and even includes a fetching tool that indicates how the bot will crawl a page, allowing you to see if there are any issues here.
Slurp Bot
The Slurp Bot is the web crawler used by Yahoo, although they use Bingbot as well to deliver their search engine results. The website owner has to allow the Slurp Bot access if they wish to have their web page content appear on Yahoo Mobile search results. Furthermore, the Slurp Bot can also access Yahoo’s partner sites to add content to their Yahoo News, Yahoo Sports, and Yahoo Finance websites.
DuckDuckBot
This is the web crawler used by DuckDuckGo, a search engine known for providing an unmatched level of privacy for its users by not tracking their activity as many popular ones do. They provide search results obtained from their DuckDuckBot, as well as crowd-sourced websites like Wikipedia, and other search engines.
Baiduspider And Yandex Bot
These are the crawler bots used by the search engines Baidu from China, and Yandex from Russia respectively. Baidu has over 80% share of the search engine market in mainland China.
How Web Crawling, Search Indexing, And Search Engine Ranking Works
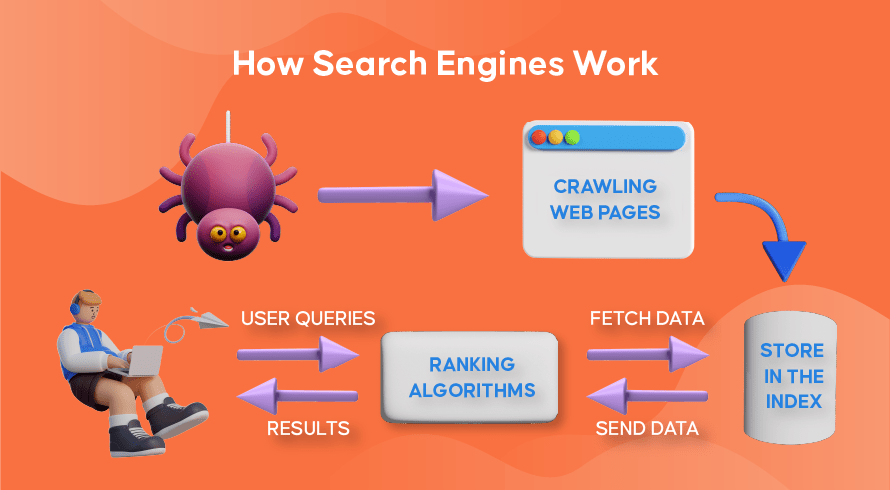
Now let’s explore how most search engines use web crawlers to find, store, organize, and retrieve information contained in websites.
How Web Crawlers Work
The process of finding both new and updated content on websites is called ‘web crawling’, hence the name for the software programs that perform this function. Bots will first start crawling a few web pages, find its content, and then follow hyperlinks included on that web page to discover new URLs, leading to even more content.
How Search Engine Indexing Works
After the bots discover new or updated content through web crawling, everything they find is added to a massive database called a ‘search engine index’. This is like a library where the books are like web pages, organized for easy retrieval later. Containing in each book most of the text contained on a web page we can see (excluding words like ‘a’, ‘an’, and ‘the’) as well as the metadata which only the crawlers see. Metadata is what search engines use to understand the content of a web page. The meta title and meta description are examples of metadata.
How Search Ranking Works
Whenever a user types in a search query, the respective search engine will check its index, find the most relevant information that matches this request, organize the list of web links that contain the relevant content, and presents this to the user in the search engine results pages (SERPs).
This organization of the SERPs is called ‘search ranking’ and is performed by a search algorithm that takes into account the data collected including metadata, the credibility of the website (authority), as well as keywords and links. Websites that are deemed to be very credible sources and contain highly relevant content that will be useful to users will rank highly, receiving the top results on the SERPs. That is why every website owner has strategies to rank their website on SERPs.
How Search Engine Optimization (SEO) Enters The Picture
Website owners can optimize the content on their pages in such a way that search engines will recognize them more easily as being relevant and useful to their users. This will push these pages to the top of the SERPs, bringing in more organic traffic to the website. Strategically including relevant keywords in the page copy, link building, and the use of original images and videos are some of the ways that SEO techniques can be utilized.
Furthermore, websites can also use various tools like SEMrush to find and fix various issues on their pages like broken links which will further improve their ranking in the eyes of search engines.
Telling Search Engines How To Crawl Your Website

Sometimes you will find that the web crawlers have not adequately performed their function, causing important pages of your website to be missing from the index. This means relevant search queries will not be presented with your content, making it difficult for potential customers to find their way to your pages. Fortunately, there are ways to communicate with search engines, allowing you a bit of control over what gets indexed and what is ignored.
The robots.txt file stored in the root directory of your website is what tells the web crawlers which pages you want to be crawled, which ones to ignore, and how your website architecture is arranged. You may wish to prevent specific pages from being indexed if they’re being used for testing, or special promotions and duplicate URLs used in e-commerce.
GoogleBot for example will still proceed to crawl a website in full if there is no robots.txt file present. When detecting your robots.txt file, GoogleBot will follow your instructions while crawling. If it has trouble detecting the file or encounters an error, it might not crawl your website. You must use the robots.txt file correctly, organize your website architecture, and use on-page SEO best practices to avoid any issues with crawling. You can perform a website audit to analyze and identify any issues that are plaguing your website.
Need SEO Services For Your Website?
If you’re looking for a services provider that understands how web crawlers and search indexing work to improve the rankings of your website, then Inquivix is the SEO partner you’ve been looking for. We provide a comprehensive set of on-page SEO services from content creation, to site architecture optimization, and website performance analysis to keep improving the quality of your website experience. To learn more, visit Inquivix On-Page SEO Services today!
FAQs
Search engines use programs called ‘web crawlers’, also known as ‘spiders’ or ‘bots’ to discover both new and updated content on a website’s pages. It will then follow links included in the page to find more pages. The content found on a page is saved in an index which is used to retrieve information for search results when a user requests it.
GoogleBot Desktop and GoogleBot Mobile are the most popular web crawlers in most countries followed by Bingbot, Slurp Bot, and DuckDuckBot. Baiduspider is used mainly in China while Yandex Bot is used in Russia.